 Cart
Cart|
Home > XML IDE - XML Editor > XML Editor Key Features > XML Pipeline > ETL - Extract, Transform, Load
XML Pipeline
ETL - Extract, Transform, LoadETL Defined (or "What Is ETL?")Extract-Transform-Load (ETL), is a process that is used to take information from one or more sources, normalize it in some way to some convenient schema, and then insert it into some other repository. A common use is for data warehousing, where regular updates from one or more systems are merged and refined so that analysis can be done using more specialized tools. Typically the same process is run over and over, as new data appears in the source application(s). Other areas include:
An ETL Use-Case and DemonstrationIn order to demonstrate this, we'll use a use-case that is similar in concept. In our ETL development example, the human resources department uses a recruiting tool written using a dBase- or FoxPro-like data structure. But the employee data is stored in Microsoft SQL Server. For reference, here is the
Our steps will be then, to Extract, Transform, and Load.
Extracting Data from the Legacy ApplicationUsing the
XML Converters,
extracting the data into something usable is very simple.
Doing just File|Open, selecting the Adding the adapter: prefix enables the converter engine. The result of this extraction will be an XML file similar to this:
<?xml version="1.0" encoding="UTF-8"?> While we are at it, let's find out what our target schema is. To do this, we use the DB to XML Data Source module. We're using the standard demonstration database that comes with SQL Server, called Northwind. To build our map, we'll use SQL/XML, which gives us any arbitrary subset of the available data. Just the defaults are fine for this demonstration. The steps are:
Now, you should see the schema of your database. Open the Northwind database and drag the Employees table onto the canvas, and choose "SELECT (SQL/XML)..." from the menu. Since we're also going to use this later to insert data into the database, switch to the UPDATE tab, and drag Employees again, but this time choose "INSERT...". 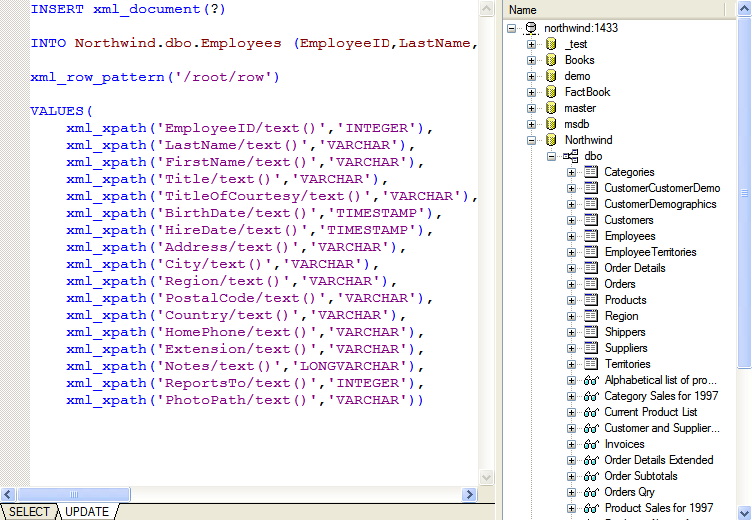 (click to enlarge) Now, save this as (For more details on SQL/XML, see the SQL/XML Tutorial. Transforming Data into the Target FormWe're going to use a series of XSLT transforms to modify this. (We could do it in one large XSLT file, we're breaking it into steps for demonstration purposes. In a production ETL operation, likely each step would be more complicated, and/or would use different technologies or methods.)
For the last step above, we can use the XSLT mapper to generate the code for us.
We use the output from the third step on the left, and the
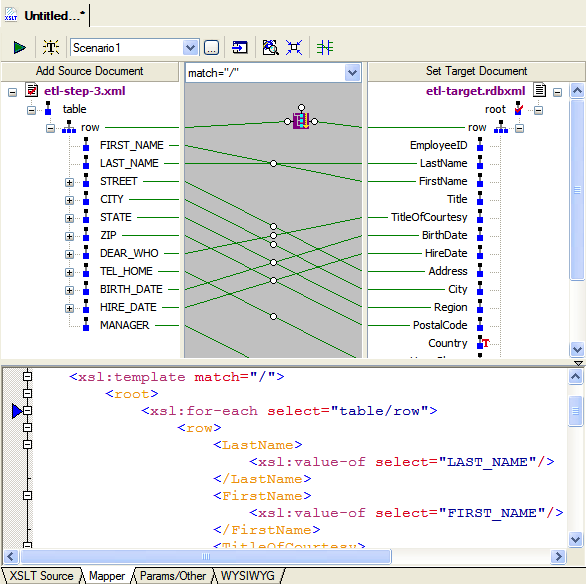
Loading Our ETL Results into the Data RepositoryAt this point, loading is a just matter of writing the output of the last XSLT
transform step into the How to Assemble the Individual ETL Steps into a Pipeline
And now we can execute our XML pipeline in the simulator it by doing XMLPipeline|Execute. Generating ETL Java CodeCreating the core of a service is as simple as pressing the
public boolean init() throws Exception { Showing the ETL LogBut we might want to see what's happening, so after that, we just have to drag
and drop over our pal Now when we run it, we'll get the input data refined, written to the database, and have as output a log of the results that should look something like this when you open the .html file:
(Titles split to make the display fit better) Our ETL ServiceAt this point, what we've done is build a service that can handle extracting information from one source, transforming it in a series of operations, and loading it into another source. We've then gone on and built a logging system, and even packaged up the whole set of steps as a single pipeline and generated the code to support it. This is only the beginning. Other steps could involve conditional processing, validation of intermediate and/or final results, error handling, and conversion to other file formats. Entire pipelines can be included as modules inside of other pipelines, and parameters can be passed in to XSLT and XQuery. See the other demonstrations for more examples on the power of XML Pipelines.
|
PURCHASE STYLUS STUDIO ONLINE TODAY!!Purchasing Stylus Studio from our online shop is Easy, Secure and Value Priced! 
Try Stylus ETL ToolsSimplify ETL design with with Stylus Studio®'s award-winning ETL programming tools — Download a free trial of our today! Attend a Live Webinar This Week!Learn about Stylus Studio's unique features and benefits in just under an hour. Register for the Stylus Studio QuickStart Training WebCast! Why Pay More for XML Tools?With Stylus Studio® X16 XML Enterprise Suite, you get the most comprehensive XML tool suite at one incredibly low price. Value: it's just one of many reasons why smart XML developers are choosing Stylus Studio! Stylus Studio® EDIFACT ZoneSimplify your next legacy data integration project with the help of the EDIFACT Zone, the world's largest, free online reference covering all EDIFACT and UN/CEFACT versions. Data Integration TechnologiesDeploy your ETL applications with Stylus Studio® X16 XML Deployment Adapters featuring powerful new Data Conversion API's |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
XML PRODUCTIVITY THROUGH INNOVATION ™



 button. Answer a couple of questions,
and code is created. Following the instructions in the generated code will let you run it. Since
Stylus Studio® contains an integrated
button. Answer a couple of questions,
and code is created. Following the instructions in the generated code will let you run it. Since
Stylus Studio® contains an integrated