Cart
Cart|
Home > Learn XML > XML Tutorials > XQuery Tutorials > XQuery Functions
XQuery Tutorials
Defining your own Functions in XQueryBy: Dr. Michael Kay I started this series of articles with a quick ten-minute tour of the XQuery language, and then followed this up with a detailed look at the workhorse of the language, FLWOR expressions. If I had been following a logical progression I would then have gone on to discuss other features of the language at a similar level of detail. Instead, I went off onto a slightly different plane, with a couple of more "strategic" articles, one on the synergies between XQuery and XML Schema, and one on the design of workflow-based applications. But I always intended to come back to a coding theme, because in the end, it's coding that matters. So in this tutorial, I want to take a look at another of the important building blocks of the XQuery language, user-defined functions. A simple XQuery functionLet's start with an example, a function to calculate the total value of a purchase order.
declare function local:order-value($po as element(purchase-order))This is written on the assumption that a purchase order looks something like this: <purchase-order>
<red-tape/> <order-item product="p010" price="10.50" quantity="2"/> <order-item product="p020" price="18.10" quantity="8"/> </purchase-order> Here's a complete query that first declares the function, and then calls it:
declare function local:order-value($po as element(purchase-order))If the sample purchase order is in the right place, running this query will compute the total and show the answer. This is what it looks like in Stylus Studio: 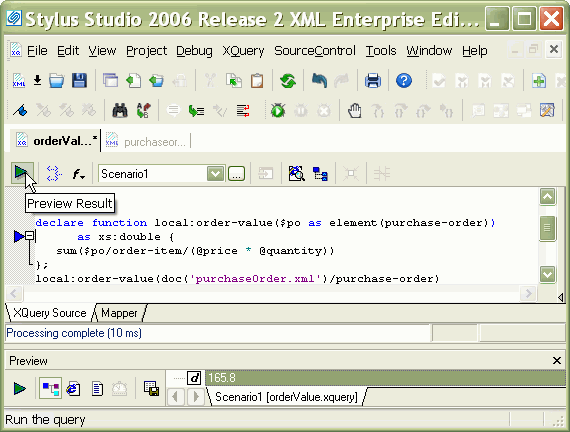
The answer is in the output preview pane at the bottom of the screen: 165.8 There are many reasons you might want to write this code as a function rather than putting it inline, and we'll look at the specific benefits in due course. In principle, of course, it's no different from writing functions or methods in any other programming language — the main advantage is that it breaks up complex code into manageable pieces. The Anatomy of a Function DeclarationNow let's look at the different parts of a function declaration in more detail. We'll highlight each part as we discuss it. One bit of trivia first: the semicolon after the closing brace at the end of the function is compulsory. XQuery can be unforgiving! (One advantage of this rule is that it makes it much easier for an XQuery parser to report multiple syntax errors in a single run. To do this, a parser needs to recover after an error, which can be a significant challenge in a language with no reserved words. The compulsory semicolon provides a solid anchor point where parsing can resume.) The function nameEvery function has a name:
declare function local:order-value($po as element(purchase-order))User-written functions are always in an XML namespace. XQuery (like XSLT and XPath before it) has extended the concept of XML names and namespaces by using namespace-qualified names not only for elements and attributes, but also for variables and functions. The namespace prefix "local" is just a shorthand for the real name of the namespace. In fact this prefix is a bit unusual, because it's predefined for you, and you aren't actually told what the real name of the namespace (the namespace URI) is. So long as your query consists of a single module, you can put all your functions in this anonymous namespace, and refer to it by the convenient prefix "local". Once you start writing production-quality XQuery applications, you will want to use multiple modules, with different namespaces for the functions in different modules: we'll see how that works later on. As you would expect, the rules for function names are the same as for XML element and attribute names: you can use a very wide range of letters and digits from any alphabet in the world, plus the punctuation characters hyphen, underscore, and period. Mathematicians can have a field day: no need to call your function sigma any more, you can call it Σ. (Well, almost: as we said earlier, it has to be in a namespace. So you'll have to make do with something like π:Σ.) You can have two functions with the same name, so long as they have different numbers of arguments. When you call a function, the system can see how many arguments are supplied in the function call, so it can work out which of the functions to invoke. In principle two such functions are completely unrelated, but in practice it's common to share a name within a group of functions that serve a similar purpose. There's no other overloading allowed: you can't have one function called XQuery Function argumentsOur example function has a single argument, but you can have any number (zero or more), separated by commas:
declare function local:order-value($po as element(purchase-order))Each argument has a name ("po" in our example — or you might prefer to think of the "$" sign as part of the name, since in XQuery they are inseparable.) The "as" clause declares the type of the argument. You can leave this out if you want: this is equivalent to writing "as item()*", and means that any type of value whatsoever is acceptable. I would recommend always declaring the expected type, for three reasons:
In the XPath 2.0 type system (which XQuery and XSLT share), every value is considered to be a sequence. A singleton value, such as a string or an integer, is just a special case — a sequence of length one. When you declare the type, you provide two pieces of information: you say what type of items can appear in the sequence, and you say how many of them are allowed. I rather rammed home the benefits of declaring types in my article on schema-aware processing — so you might be forgiven for thinking that if you're not using a schema, you can ignore anything that mentions types. You'd be wrong: without a schema, you can't refer to user-defined types, but there's still a lot of mileage simply in using the built-in types that are available whether you use schemas or not. The items may be either nodes or atomic values. In our example, the function takes a node as its input, and returns an atomic value (an xs:double) as its result. The nodes will usually be elements, but they can also be attributes or any of the other kinds of node: document nodes, text nodes, even comments or processing instructions. In the function signature you can constrain what kind of nodes are allowed. Here are some examples:
This allows you to be as specific or as general as you want. In our example, we used the form For atomic values, you can use the names of the built-in types defined in XML Schema, such as The final part of an XPath type is the cardinality: telling the system how many items are allowed in a sequence. You're not allowed to put numeric limits on this, instead you can use one of the four occurrence indicators:
The result typeOur example function returned an
declare function local:order-value($po as element(purchase-order))As with the argument types, you don't need to declare the result type, but I would strongly recommend it, for the same reasons. When you call a function, the system will make some limited adjustments to the values you supply in the function call to turn them into values of the right type. Similarly, the result computed by the function body will be adjusted if necessary to fit the declared return type. The adjustments that are made are:
The system won't automatically convert values across the type hierarchy, for example it won't convert an integer to a string or a string to an integer. Also, it won't convert down the type hierarchy. If your function is declared to expect an The function bodyThe function body is the bit that does the work!
declare function local:order-value($po as element(purchase-order))The body of the function can be any expression. Note that there is no "return" keyword at the start, and no semicolon at the end: it's an expression, not a statement. Within the function you can refer to the arguments defined for the function; you can also refer to variables declared locally in a let clause, or to global variables declared in the query prolog. You can also refer to user-defined functions defined anywhere in the same module (including forwards references) or in an imported module (we'll be looking at library modules later). Because a function can contain any expression, it's not confined to calculating values: it can also construct new nodes. You can write a function that is rather like an XSLT template:
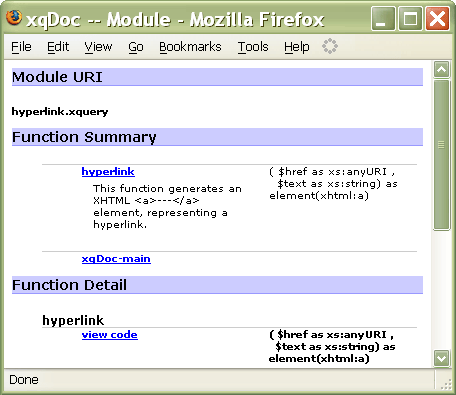
declare function local:hyperlink($href as xs:anyURI, $text as xs:string)This time the arguments are atomic values and the return type is a node. One thing that you can't do, which comes as a bit of a surprise if you've become accustomed to XSLT, is refer to the context node. There's no implicit parameter passing: if you refer to "." at the top level of the function body, you will get an error saying the context node is undefined. The reason for this restriction is that it makes it much easier for the compiler (and for that matter, anyone coming along to modify your query) to work out what information the function depends on. Speaking of DocumentationYour eyes probably glazed over when you saw the word "documentation", but I mentioned that one of the benefits of declaring your types is that it makes your functions easier to understand for people who have to maintain your code. But what about people who want to call your functions? Where is the equivalent of Java's javadoc tool? There's nothing like this in the W3C XQuery specification, but an emerging standard in this area is the xqDoc tool written by Darin McBeath. Like javadoc, this makes use of structured comments which are understood by the documentation tool, but ignored by the XQuery compiler. The Stylus Studio query editor makes it easy to generate xqDoc comments in your source code, and then to run the tool to produce HTML documentation. Here's what the previous function looks like with xqDoc comments:
declare namespace xhtml="http://www.w3.org/1999/xhtml";All you need to do in Stylus Studio is select XQuery/Generate xqDoc, and here is the result viewed in the browser:
This completes our quick tour of the anatomy of a function declaration. In the next section we'll look at how functions are assembled into modules; and then we'll examine some of the practical ways of taking advantage of functions when it comes to writing XQuery applications. ModulesAlthough most of the queries you'll see in tutorials are less than a dozen lines long, it's possible to write sophisticated applications entirely within XQuery. To achieve this, you need to apply the usual software engineering disciplines of breaking up your code into components. In XQuery, these components are called modules. Within an application, there will always be one main module, and there may also be any number of library modules. A main module can import or more library modules using an
module namespace m1 = "http://example.org/module1";
and the importing module imports it (like an import declaration in Java or a using declaration in C#):
import module namespace m1 = "http://example.org/module1";
Both the library module and the importing module have declared a namespace prefix for use with the module namespace: in this case they have chosen the same prefix, but as always, that's just a matter of convention. When it finds an
import module namespace m1 = "http://example.org/module1"How this works in detail is something you'll have to find out from the vendor's product documentation. As you might expect, you can import a library module into another library module, as well as importing it into your main query. Unlike XSLT (but like Java and C#), imports don't cascade: you only get access to the functions and variables declared in the modules you import directly, not those that it imported from elsewhere. There's a big gotcha here, which is that the W3C specification does not allow cyclic imports: if A imports B, then B cannot import A, directly or indirectly. This is such a nasty restriction (and such an unnecessary one) that it wouldn't surprise me to see vendors relaxing the rule in their products. The language specification allows several modules to share the same namespace. In this case, when you import the namespace, you import all the modules. If you want to make calls from one module into another module with the same namespace, you need to import your own namespace. This is the one situation where cyclic imports are allowed: if modules A and B are in the same namespace, then they can both import their own namespace, so everything in A can access everything in B, and vice versa. We'll be using modules in a live example later on. Modules and SchemasWhen you use multiple modules in a schema-aware query, there are a few extra points you need to bear in mind:
Using FunctionsWhen would you want to use functions? There are two particular uses I would like to highlight: use of functions to mask the complexity of a schema, and the use of functions for recursive queries. Masking Schema ComplexityMany schemas used in the real world are hideously complex. Simple documents like purchase orders, by the time they are standardized across an industry and made to conform to the accounting rules of every country in the world, end up with hundreds of optional elements and deep hierarchic structures. In this environment, writing simple queries (how many widgets did we sell in April?) can become a nightmare, because the information is so deeply buried. Very often, the people who have to write the queries are end users or business analysts who don't want to understand all the technical complexity of the data. In this environment, a well-designed library of functions can make users' lives a lot easier. The author of the function library needs to understand the complexities of the schema, but the author of the query does not. There are a number of ways of writing helper functions that achieve this goal:
Recursive QueriesThe real power of XQuery functions comes when they are recursive: that is, when a function calls itself, directly or indirectly. There are some queries that simply cannot be done without the use of recursive functions. Suppose we want to find all the employees who report to a given manager, directly or indirectly. We'll assume the existence of a navigator function Now we can write a function that computes the direct-or-indirect reports:
declare function hr:allReports($e as element(employee))The result of this function is the union ("|" operator) of the direct reports, plus the direct reports of the direct reports, and so on recursively. The only trouble with this function is that if there is a cycle in the data (two employees who report to each other, for example) then this will cause infinite recursion, probably resulting in a stack overflow. But we can write a version of the function that checks for this condition. We need to pass an extra parameter containing the list of managers found so far, and if we find any of these again, we know we have a cycle. We'll call this extra argument $guard, and we'll write the function so that
declare function hr:allReports($e as element(employee), $guard as element(employee)*) as element()* {We can then call the function to find all the subordinates of Notice how we wrote this without any knowledge of the actual XML source document: all we knew was that there was a navigator function hr:directReports() available. This is a common coding pattern in functional programming languages. Sadly, however, XQuery is missing one feature that other functional programming languages use heavily: the function We can test this out in Stylus Studio using an XML document like this:
<employees>
Main Query:
import module namespace hr = "http://hr.example.com/" at "hr-module.xquery";Library Module:
module namespace hr = "http://hr.example.com/";Run the query: the answer is "true". Edit the data to remove the cycle, and the answer changes to "false". Recursive functions can be difficult to master: I admit I made a few errors while developing these simple functions, and it can be difficult to see where you have gone wrong (although using an XQuery Debugger can help). But it's well worth making the effort, because any programming of any complexity in XQuery needs them. They're needed not only for the tasks that you might think of as being naturally recursive (like finding a manager's indirect reports) but also for many more mundane jobs which in other languages would be done using loops and mutable variables: for example working out the running total of the amount in a bank balance, given details of the deposits and withdrawals. Summary: XQuery Functions in a NutshellLet's recap. Simple queries, including many of those you'll find in tutorials and text books, often consist of a single FLWOR expression written in less than a dozen lines of code. But you can also write serious applications in XQuery, and to do that you need to split the application into reusable components. In XQuery, those components are modules and functions. We saw that there are really two roles for functions in XQuery. Firstly, they are very useful as a mechanism for hiding complexity, particularly the sort of complexity found in industry schemas containing hundreds of different element types. In that situation, a library of helper functions can make it much easier to write queries. We looked at three particular kinds of helper functions: Secondly, recursive functions can perform tasks that cannot be done any other way. We looked at the example of finding all the employees who report to a manager directly or indirectly, and at the more difficult example of finding whether there are any cyclic dependencies in the data. All in all, functions have a useful function! Editor's Note: Check out Dr. Michael Kay's other XQuery articles in this series including:
|
PURCHASE STYLUS STUDIO ONLINE TODAY!!Purchasing Stylus Studio from our online shop is Easy, Secure and Value Priced! 
Try Stylus Powerful XQuery IDEDownload a free trial of our award-winning IDE for XQuery today! Learn XQuery in 10 Minutes!Say goodbye to 10-minute abs, and say Hello to "Learn XQuery in Ten Minutes!", the world's fastest and easiest XQuery primer, now available for free! Ask Someone You KnowDoes your company use Stylus Studio? Do your competitors? Engineers from over 100,000 leading companies use Stylus Studio, and now you can ask someone from your own organization about their experiences using Stylus Studio. Top Ten XQuery TrendsRead about the top 10 XQuery Trends and how they will impact change the way enterprise software applications are built. |
XML PRODUCTIVITY THROUGH INNOVATION ™