Cart
Cart|
Home > Learn XML > XML Tutorials > My Gutenberg Project by Dana Pearson
My Gutenberg Projectby Dana Pearson, www.dbpearsonmlis.com The Gutenberg Project has it roots in the early 70's and is an example of a big idea that started small. I first learned of the Project as a graduate student in the early 90's. As a student of the library and information sciences, I realized that this, gopher and Berners-Lee's revolutionary HTML would have a profound impact and not only on libraries. A couple of decades later after a career primarily as a college library director, I decided to make a career change that would require re-tooling. My primary interest was integrating online resources into library discovery systems. It seemed to me that XML technologies would be well suited to working with metadata of various types including the electronic format library catalog records that have been used by libraries since its development in the 1960's. An XML format was developed by the same institution that developed the original version, the Library of Congress. I decided to crosswalk the RDF/Dublin Core metadata offered by Project Gutenberg in August, 2012. Libraries have done so for years but ony because they had the necessary expertise on staff to do so. I wanted to make this rich collection of ebooks available to any libary that wanted to make it discoverable within their systems but that motivation only came after another motivation. With the free time available, I began to create the stylesheet to transform the metadata into MARCXML primarily as a learning experience to extend my XSLT skills. Along the way, I was able to extend a rudimentary understanding of regular expressions into proficiency. The most satisfying aspects of the project were the problems that required learning something new about XSLT 2.0. The analyze-string element along with regular expressions were essential for transforming strings of author, title, and subject since the metadata collapsed content into a single string. MARCXML requires subelements with attributes that required condition testing of a variety of sorts. Another problem was that the Gutenberg metadata largely used two character codes for the representation of the ISO-639 standard for language. Library standards require the three letter version. So I created a separate XML file with a stylesheet to transform the content of a screen capture of an HTML page with both two and three character codes along with the name of the language. This XML file was then used along with a test of the length of the character string in the dc:language element and, when less than three, to substitute the three character code to create suitable content for the MARCXML in three relevant elements. Having successfully completed the stylesheet, however, there remained a considerable amount of editing for decisions only a human can make, or at least, one trained in library cataloging and classification. For example, RDF/DC metadata segment:
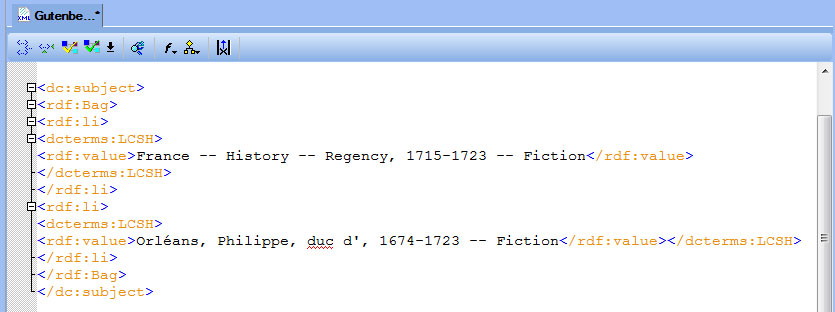
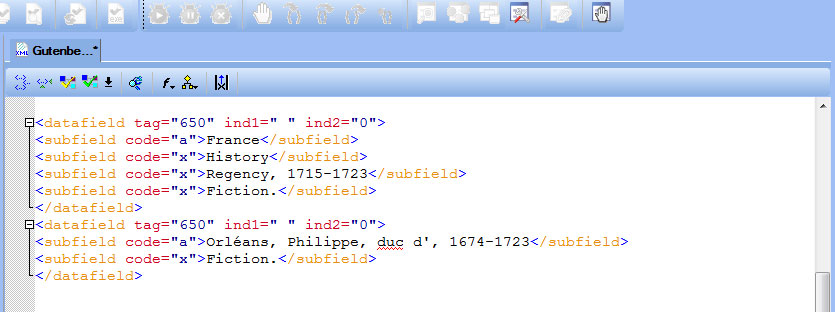
The subject heading strings contained in the dc:subject element are inadequate for library catalog records. The stylesheet creates the following MARCXML record segment:
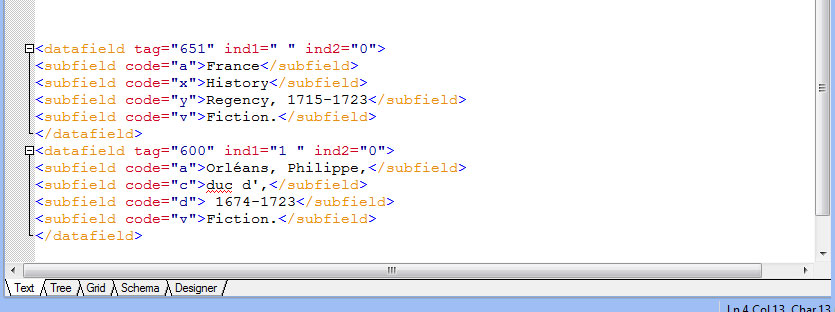
Library cataloging standards require different tag attribute codes for different types of subjects such as general subject headings, persons as subjects and geographical entity as subject. Moreover, subheadings within subfields requires different code attributes with respect to subheadings related to general headings, genre, geospatial and temporal headings.
The library application I used for the editing is the same one that transformed the MARCXML to MARC and provides robust editing tools. A very large number of automated replacement tasks were created including a number of regular expressions to redistribute strings across subfields. The editing began in January, 2013 since by September, 2012, I suddenly had no free time. Having only a two or three hours per day, I was able to finish the editing the 40,000 plus records in May. The records are available at the Internet Archive. My website, www.dbpearsonmlis.com, has the announcement.
|
PURCHASE STYLUS STUDIO ONLINE TODAY!!Purchasing Stylus Studio from our online shop is Easy, Secure and Value Priced! 
Try Stylus Powerful XQuery IDEDownload a free trial of our award-winning IDE for XQuery today! Learn XQuery in 10 Minutes!Say goodbye to 10-minute abs, and say Hello to "Learn XQuery in Ten Minutes!", the world's fastest and easiest XQuery primer, now available for free! Ask Someone You KnowDoes your company use Stylus Studio? Do your competitors? Engineers from over 100,000 leading companies use Stylus Studio, and now you can ask someone from your own organization about their experiences using Stylus Studio. Top Ten XQuery TrendsRead about the top 10 XQuery Trends and how they will impact change the way enterprise software applications are built. |
XML PRODUCTIVITY THROUGH INNOVATION ™